Protecting User Data in AI Memory Systems: The MemPrivacy Approach
As large language models (LLMs) powering AI agents move from labs to real-world applications, a critical tension emerges: the more useful cloud-based memory becomes, the more private user data it exposes. Researchers from MemTensor (Shanghai), HONOR Device, and Tongji University have developed MemPrivacy, a framework designed to resolve this dilemma without sacrificing the utility that makes personalized memory valuable. Below, we explore the challenges, existing solutions, and how MemPrivacy offers a fresh perspective through local reversible pseudonymization.
1. What is the core privacy problem with cloud-based AI memory?
When you interact with an AI agent—whether for drafting emails, managing health data, or handling finances—your conversations often contain sensitive details like health conditions, email addresses, financial figures, and passwords. In a typical edge-cloud setup, your device (the edge) processes input, while the cloud handles heavy memory management and reasoning. This architecture is efficient but means raw, unfiltered user data travels to and persists in cloud systems. Once sensitive content enters cloud logs, vector databases, or external memory stores, it can remain accessible far beyond the original interaction. The risk is not theoretical: studies show that multi-turn memory attacks can induce privacy violations with up to 69% success, and leakage attacks against memory systems can reach 75% success. Indirect prompt injection can even manipulate agents into actively soliciting private information from users.
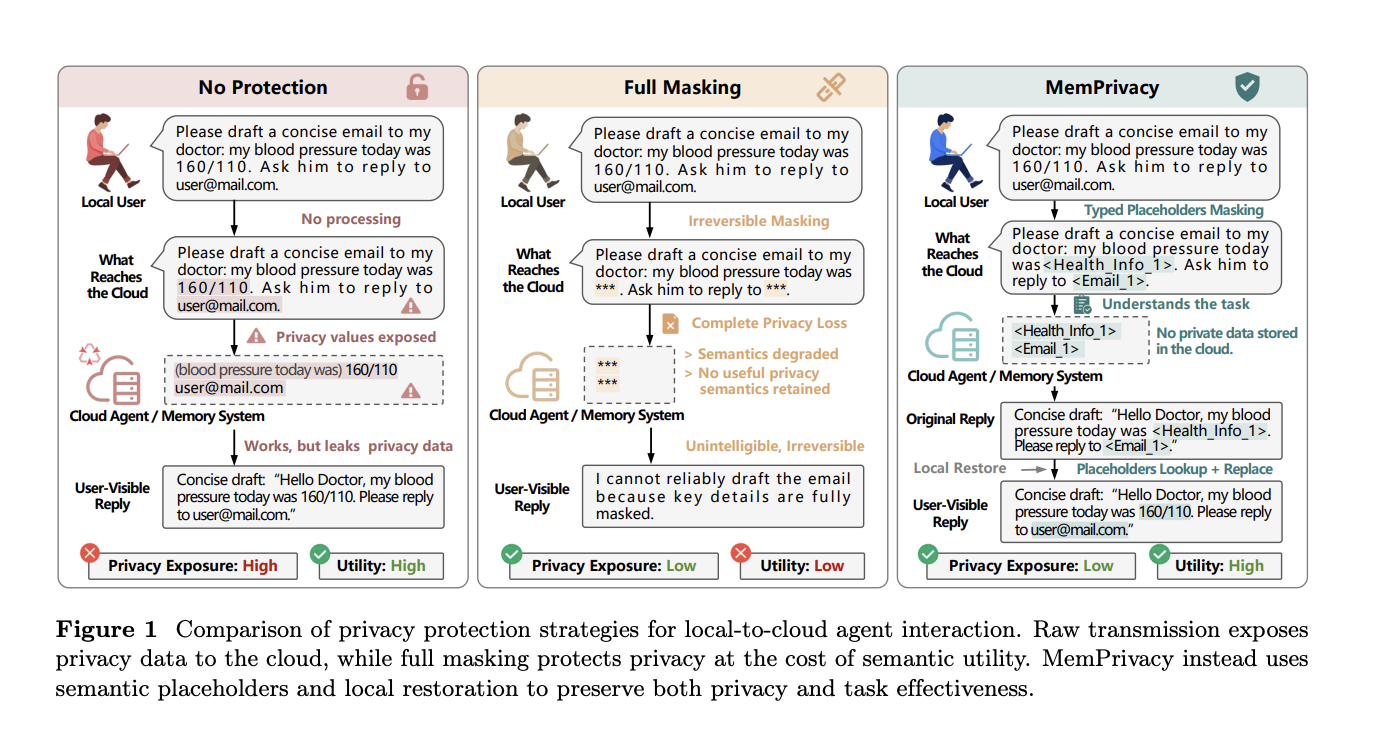
2. Why do older privacy methods like masking fall short?
Previous attempts to protect privacy often relied on masking—replacing sensitive values with generic tokens like ***. While simple, this approach destroys semantics. For instance, if a user asks an agent to draft a doctor’s email and both their blood pressure reading and email address are replaced with ***, the cloud model cannot complete the task meaningfully. More advanced techniques such as differential privacy and cryptographic protection offer stronger guarantees but are difficult to integrate into interactive memory pipelines without degrading response quality. They either add noise that disrupts reasoning or require heavy computation that slows down real-time interactions. The challenge is to protect privacy without breaking the utility that makes memory useful—something masking and other methods have struggled to achieve.
3. How does MemPrivacy solve the tension between privacy and utility?
MemPrivacy introduces a novel approach called local reversible pseudonymization. Instead of masking private content, it replaces sensitive data with typed placeholders—structured tokens like <Health_Info_1> or <Email_1>—before the input leaves your device. The cloud receives semantically intact text and can reason and store memories normally; it simply never sees the actual values. When the cloud returns a response containing these placeholders, your device looks up the originals from a secure local database and substitutes them back. You see a fully coherent, personalized response. This design preserves the cloud’s ability to process memory without exposing raw details, effectively resolving the core tension between utility and privacy.
4. What are the three stages of MemPrivacy’s pipeline?
MemPrivacy operates in three distinct stages:
- Stage 1: Uplink Desensitization – A lightweight on-device model identifies privacy-sensitive spans in the input, classifies each by type (e.g., health info, email) and sensitivity level, and replaces them with typed placeholders. The original-to-placeholder mappings are stored locally, encrypted for security.
- Stage 2: Cloud Processing – The cloud receives the placeholder-rich text and performs memory management and reasoning normally. It can store, retrieve, and process memories without ever seeing the actual private values.
- Stage 3: Downlink Restoration – When the cloud returns a response containing placeholders, the local device retrieves the originals from its secure database and substitutes them back in real-time. The user sees a complete, personalized output.
This pipeline ensures that sensitive data never leaves the device in plain text, while the cloud retains full semantic utility.
5. How does MemPrivacy differ from differential privacy and cryptography?
Unlike differential privacy, which adds noise to obscure individual data points—often degrading model accuracy—MemPrivacy preserves exact semantics by keeping original values local. Cryptographic methods, such as homomorphic encryption, allow computation on encrypted data but are computationally heavy and difficult to integrate into interactive memory pipelines. MemPrivacy’s local reversible pseudonymization is lightweight and fast: the on-device model runs efficiently, and placeholders require no special processing from the cloud. This makes it practical for real-time AI agents, whereas differential privacy and cryptography often introduce latency or loss of fidelity. The key innovation is that MemPrivacy maintains full utility for the cloud while ensuring that raw data never leaves the user’s device, striking a practical balance that previous techniques could not achieve.
6. Can MemPrivacy protect against indirect prompt injection and memory attacks?
Yes, MemPrivacy significantly reduces the risk of both direct and indirect privacy violations. Indirect prompt injection attacks manipulate agents into eliciting private information from users; because the cloud never sees raw data, there is no sensitive content to extract. Similarly, multi-turn memory attacks and leakage attacks rely on accessing persisted data in cloud logs or vector databases. Since MemPrivacy only stores placeholders in the cloud, even if an attacker gains access to cloud memory, they only see meaningless tokens like <Health_Info_1>. The actual values remain encrypted on the user’s device, which is not accessible via cloud-side attacks. This effectively neutralizes the 69-75% success rates observed in prior studies, giving users a much stronger privacy guarantee without compromising the agent’s ability to provide personalized responses.
Learn more: For deeper technical details, see the original paper on arXiv.
Related Articles
- Google's Pixel Screenshots App Breaks Free: Desktop Version Spotted, Hints at Aluminium OS Launch
- AI Coding Wars: Vibe vs Spec — The Battle for Software Development's Future
- APK Downloader 'apkeep' Reaches Version 1.0.0, Enabling Deeper Android App Security Research
- Survey Reveals Smartphone Upgrade Priorities: Price, Battery, Storage Trump Foldables and AI
- Revopoint POP 4: AI-Driven 3D Scanner Revolution with Gaussian Splatting on Kickstarter
- Red Blades on the Horizon: 10 Key Insights into Reducing Bird Collisions with Wind Turbines
- How to Scale Your Cloud and AI Operations with Microsoft Azure in Europe
- Rivian R2: Affordable Electric SUV with Premium Features, Variants, and Potential In-House Lidar