Kubernetes v1.36 Brings PSI Metrics to General Availability: Early Warning System for Resource Contention Now Stable
Kubernetes v1.36 Makes PSI Metrics Production-Ready: Early Detection of Resource Saturation Now Stable
The Kubernetes community today announced that Pressure Stall Information (PSI) metrics have graduated to General Availability (GA) with the release of v1.36. This means operators can now rely on a stable, built-in interface to detect memory, CPU, and I/O contention at the node, pod, and container levels before it causes downtime.
Unlike traditional utilization metrics that show only aggregate usage, PSI tracks the percentage of time tasks are stalled due to resource pressure. This provides high-fidelity signals for identifying saturation early—before it escalates into an outage.
"PSI fills a critical gap that has been present since the early days of container orchestration: you can have 70% CPU usage on a node and still suffer severe latency because of scheduling delays," explained Dr. Maria Chen, lead SIG Node contributor. "With this graduation, we're giving every Kubernetes user the same telemetry that large-scale operators have used internally for years."
Background: What Is PSI and Why Does It Matter?
Pressure Stall Information was first introduced in the Linux kernel in 2018. It measures how long tasks are delayed or stalled while waiting for CPU, memory, or I/O resources. The metric is expressed as a percentage of time over three windows—10 seconds, 60 seconds, and 300 seconds—allowing operators to distinguish between transient spikes and sustained pressure.
Before PSI, administrators relied on utilization percentages (e.g., 80% CPU) which can mask underlying contention. A node at 60% utilization might still be causing task stalls due to resource competition. PSI directly reports those stalls.
"For years the only way to get this data was to instrument applications or rely on external monitoring tools. PSI bakes it into the kernel and now Kubernetes exposes it natively," said Alex Rivera, staff engineer at a major cloud provider and member of the Kubernetes metrics working group.
Performance Testing at Scale: Proving Stability
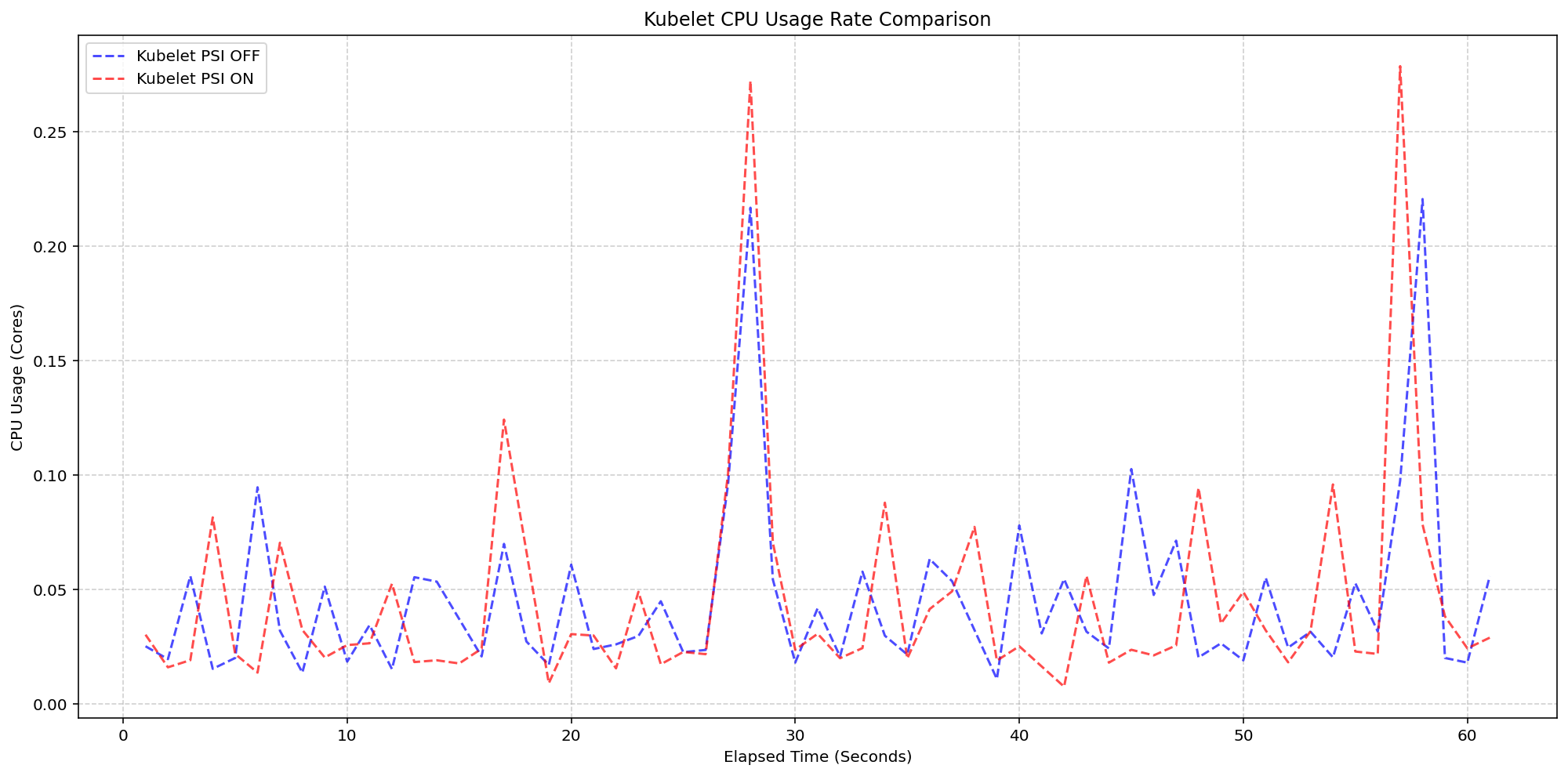
A major concern when graduating telemetry features is the overhead of collecting and exposing metrics. The SIG Node team conducted extensive validation on high-density workloads—80+ pods—across different machine types. Two scenarios isolated the impact of the kubelet and kernel-level collection.
Scenario 1: Kubelet Overhead
On 4-core machines with the kernel already tracking PSI (psi=1), the team toggled the KubeletPSI feature gate. The result: kubelet CPU usage was nearly identical whether PSI was enabled or disabled. The synchronized bursts in resource usage matched exactly in magnitude and frequency.
"The kubelet's PSI collection logic is so lightweight that it blends into normal housekeeping cycles. We measured less than 0.1 cores—about 2.5% of node capacity—which is negligible for production deployments," reported Kevin Okonkwo, SIG Node performance lead.
Scenario 2: Kernel Overhead
In the second test, the team compared clusters with kernel PSI tracking turned off versus on. System CPU usage showed only a slight, expected increase when the kernel was actively tracking pressure. Once the OS is recording PSI data, the act of Kubernetes reading those cgroup metrics adds virtually no extra load.
"We wanted to make sure there was no hidden penalty for enabling PSI at the kernel level. The results confirm the overhead is minimal and well within acceptable ranges for all common machine sizes," added Okonkwo.
What This Means for Operators
With PSI metrics now GA, Kubernetes administrators can build alerting and autoscaling policies that react to actual resource contention rather than proxy metrics like utilization. This reduces false positives and enables earlier intervention.
For example, a sudden spike in memory pressure PSI can trigger a pod rescheduling or node scaling before OOM kills occur. Similarly, sustained CPU pressure can signal the need for vertical pod autoscaling or workload rebalancing.
"This is a paradigm shift. Operators no longer need to guess whether a node is 'fine' because utilization is below 80%. They now have direct insight into when tasks are waiting—and that's what ultimately affects application performance," said Dr. Chen.
Key Metrics Exposed
The GA feature exposes two types of PSI data per resource (CPU, memory, I/O):
- Cumulative Totals: Absolute time spent in a stalled state since boot, allowing calculation of average pressure over any interval.
- Moving Averages: Percentages over 10s, 60s, and 300s windows to distinguish short bursts from sustained issues.
These are available at node, pod, and container levels through the kubelet metrics endpoint, enabling integration with Prometheus and other monitoring stacks.
Looking Ahead
The graduation of PSI metrics marks a milestone in Kubernetes observability. Future work may include better integration with cluster autoscalers and native dashboards, but today's release gives operators a solid foundation.
"We've been running PSI internally for months and it has caught multiple near-miss incidents before they became user-facing problems. I highly recommend enabling it for all production clusters," urged Rivera.
To get started, upgrade to Kubernetes v1.36 and enable the KubeletPSI feature gate. Documentation is available in the Kubernetes metrics documentation.
Related Articles
- Canonical Under Fire: Ubuntu Servers Crippled by Sustained DDoS Attack, Pro-Iran Group Claims Responsibility
- Ubuntu Down for Over 24 Hours After Sustained DDoS Attack; Pro-Iran Group Claims Responsibility
- Testing Sealed Bootable Container Images for Fedora Atomic Desktops
- Making Transparent Huge Pages Truly Massive: The Push for 1GB Support
- LWN.net Weekly Edition: April 30, 2026 - In-Depth Q&A
- Linux Kernel Introduces Emergency Kill Switch for Vulnerable Functions
- Strawberry Music Player Emerges as Leading Linux Music Management Solution
- Major Security Patch Rollout: Linux Distributions Release Critical Fixes Across Dozens of Packages