6 Key Insights into Zyphra’s TSP: The Hardware-Aware Parallelism Strategy Boosting Throughput by 2.6x
Training and deploying large language models is a delicate balancing act. Every GPU in a cluster has finite VRAM, and as model sizes and sequence lengths increase, engineers must constantly decide how to split workloads across hardware. Zyphra’s new Tensor and Sequence Parallelism (TSP) technique offers a fresh approach to this trade-off. In benchmark tests on up to 1,024 AMD MI300X GPUs, TSP consistently reduces per-GPU peak memory and delivers up to 2.6× higher throughput than traditional parallelism schemes. This listicle breaks down six crucial aspects of TSP, from its foundational concepts to its impressive real-world performance.
1. What TSP Stands For and Why It Matters
TSP stands for Tensor and Sequence Parallelism. It’s a hardware-aware strategy designed to optimize both training and inference of large transformer models. Unlike standard approaches that treat tensor and sequence parallelism as separate dimensions, TSP folds them together. This simple shift dramatically lowers peak memory usage per GPU—making it feasible to train bigger models or use longer contexts without upgrading hardware. For AI teams wrestling with memory bottlenecks, TSP provides a practical path to higher performance without sacrificing model quality.
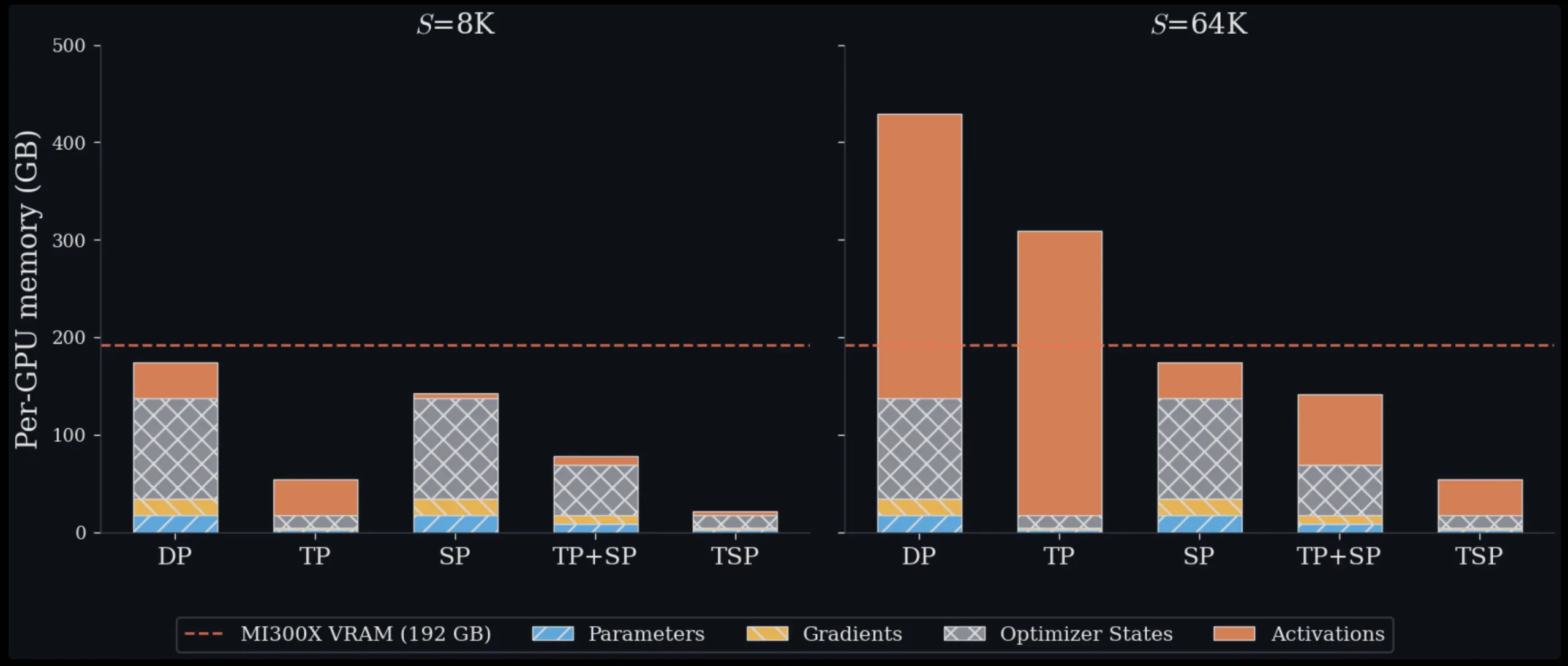
2. The Memory Management Challenge at Scale
Scaling transformers requires solving a fundamental memory problem. Each GPU has a fixed amount of VRAM used for parameters, gradients, optimizer states, and activations. When models grow, engineers must distribute these components across multiple devices. Standard parallelism methods force trade-offs: some reduce parameter memory but increase communication overhead, while others lower activation memory but leave parameters fully replicated. TSP addresses this by simultaneously sharding both weights and sequences on the same axis, effectively breaking the memory-communication trade-off. As a result, it achieves lower peak memory than any current baseline for both training and inference.
3. Understanding Tensor Parallelism (TP) and Its Trade-offs
Tensor Parallelism splits model weights across GPUs. In an attention or MLP layer, each GPU in the TP group holds only a fraction of the weight matrix. This directly reduces memory used for parameters, gradients, and optimizer states (the “model state”). However, TP requires costly collective communication—all-reduce or reduce-scatter/all-gather pairs—each time a layer is computed. Because communication volume scales with activation size, TP overhead becomes increasingly expensive as sequence lengths grow. For long-context models, this communication can dominate runtime, limiting scalability.
4. Understanding Sequence Parallelism (SP) and Its Trade-offs
Sequence Parallelism takes a different path: it splits the input token sequence across GPUs, so each device processes only a fraction of the tokens. This reduces activation memory and the quadratic cost of attention computation. But SP leaves model weights fully replicated on every GPU, meaning model-state memory stays constant no matter how many GPUs you add. This makes SP memory-inefficient for large models, because each GPU must store the entire parameter set. Combining TP and SP in standard multi-dimensional parallelism uses more GPUs for the model-parallel group, leaving fewer for data parallelism and often forcing slow inter-node communication.
5. The Innovation: Folding TP and SP into One Dimension
TSP’s core idea is parallelism folding. Instead of placing TP and SP on separate orthogonal mesh dimensions, Zyphra collapses both onto a single device-mesh axis of size D. Every GPU in the TSP group simultaneously holds 1/D of the model weights and 1/D of the token sequence. This unified sharding reduces per-GPU peak memory for both model state and activations. Because the sharding axis is one-dimensional, TSP can better exploit high-bandwidth intra-node interconnects (like AMD Infinity Fabric or NVIDIA NVLink), avoiding slower inter-node links. The result is a leaner, faster parallel configuration that requires fewer GPUs per model replica.
6. Benchmark Results: Up to 2.6x Throughput on 1,024 GPUs
Zyphra tested TSP against standard TP+SP baselines using up to 1,024 AMD MI300X GPUs. Across both training and inference workloads, TSP consistently delivered 2.6× higher throughput while using less GPU memory per device. The key driver is reduced communication overhead and more efficient use of intra-node bandwidth. For engineers deploying large language models, this means faster iteration, lower infrastructure costs, and the ability to handle longer contexts without out-of-memory errors. TSP is open-source and available now, offering a practical upgrade for any transformer-based system.
TSP tackles a core problem in large-scale transformer deployment: memory-communication trade-offs. By folding tensor and sequence parallelism into one dimension, Zyphra achieves lower peak memory and higher throughput. Whether you’re training a billion-parameter model or serving long-context inference, TSP is a hardware-aware strategy worth evaluating. For more details, check the official Zyphra announcement.
Related Articles
- How to Snag the Ultimate Lenovo Gaming PC Deal: RTX 5090, Intel Core Ultra 9, and $2,000 Off
- Hackaday Podcast 369: From PCB Shortages to Flow Batteries and Leaded Fuel
- GPU-Based Rowhammer Attacks: New Threats to NVIDIA Systems and Host Memory
- NVIDIA and Ineffable Intelligence Forge Path to Next-Generation Reinforcement Learning Infrastructure
- Intel's Crescent Island GPU Gains Major Linux Driver Boost for AI Inferencing
- Beyond 2nm: Six Parallel Technologies to Power Next Computing Era, Say Experts
- Credit Card-Sized ESP32 Computer Hits the Scene: Tiny, DIY, and Fully Functional
- OpenAI's MRC Protocol: Solving the Networking Bottleneck in AI Supercomputer Training